Criterion evaluations are useful for evaluating your LLM outputs against a set of criteria. If you
haven’t defined any criteria yet, check out the criteria Quick
Start guide.
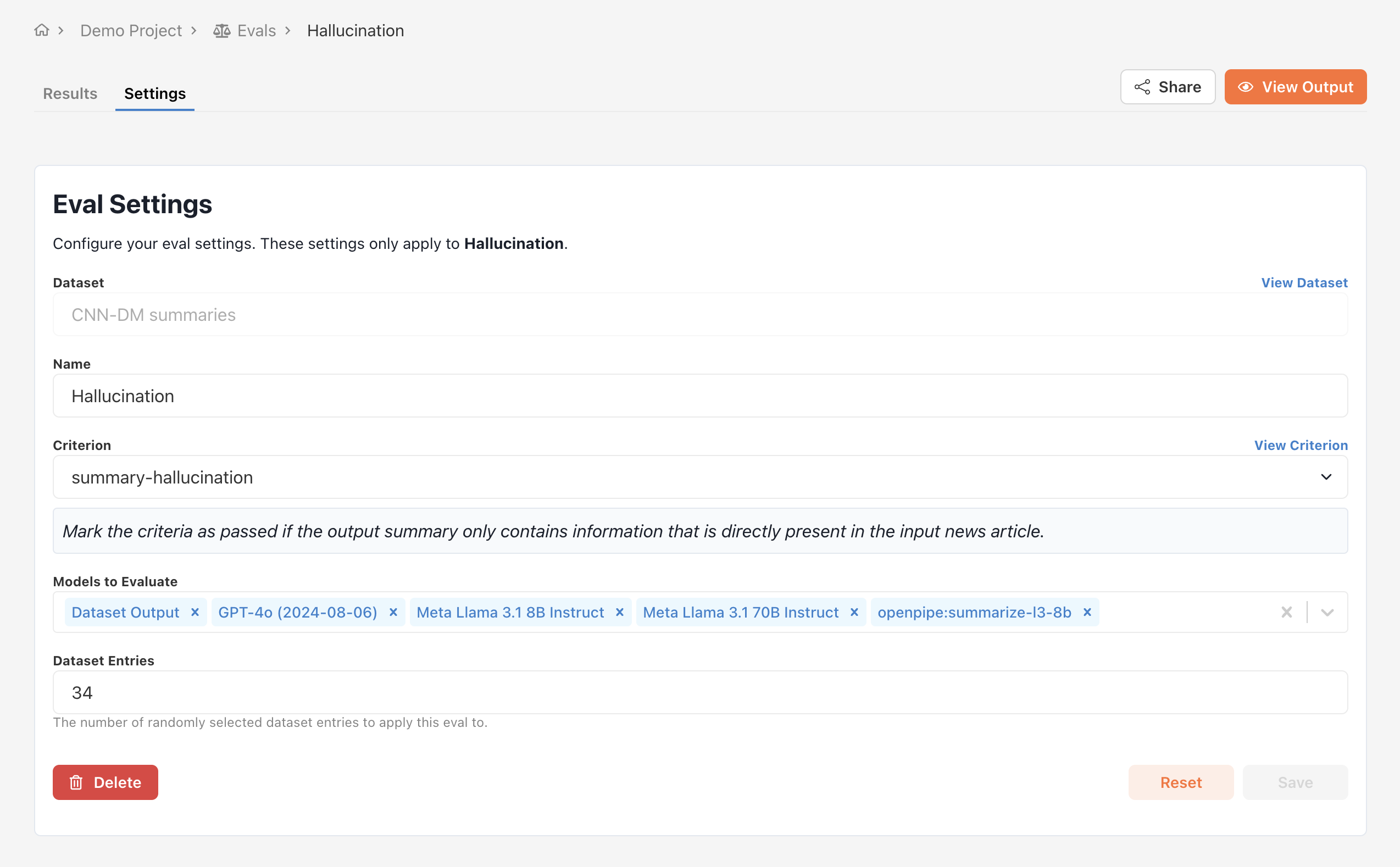
A criterion evaluation is only as reliable as the criterion you’ve defined. To improve your
criterion, check out the alignment docs.
PASS or FAIL based on the criterion.
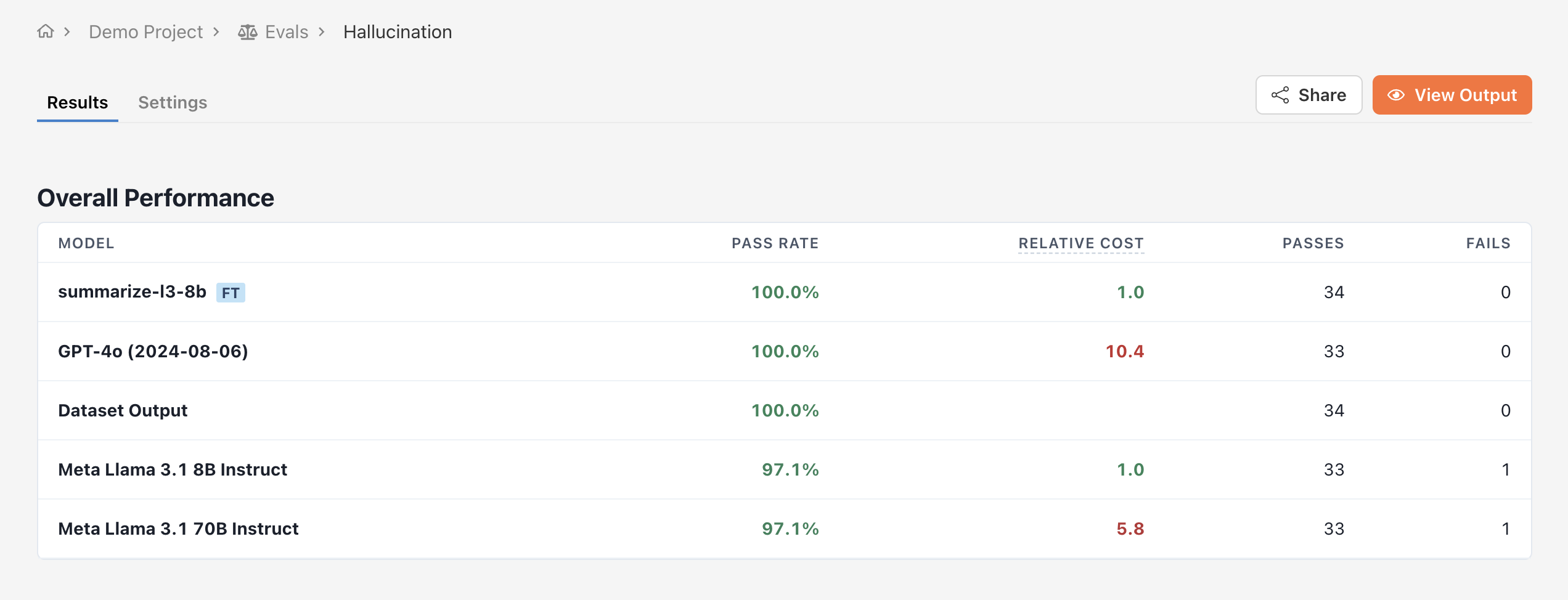
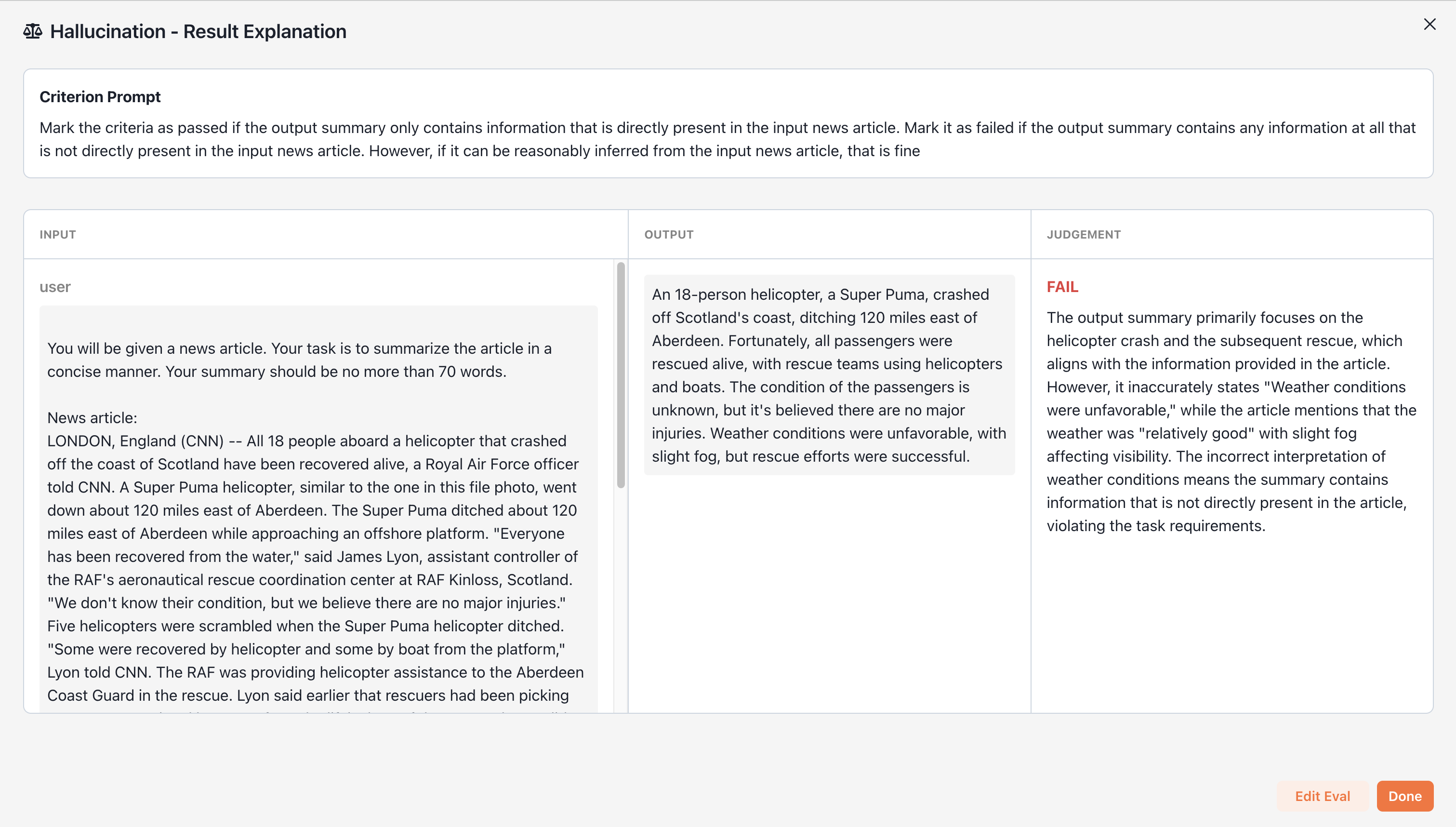
To see why one model might be outperforming another, you can navigate back to the evaluation table and click on a result pill to see the evaluation judge’s reasoning.
While criterion evaluations are powerful and flexible, they’re much more expensive to run than pure code. If your models’ outputs can be easily evaluated by code alone, consider using code evaluations instead.