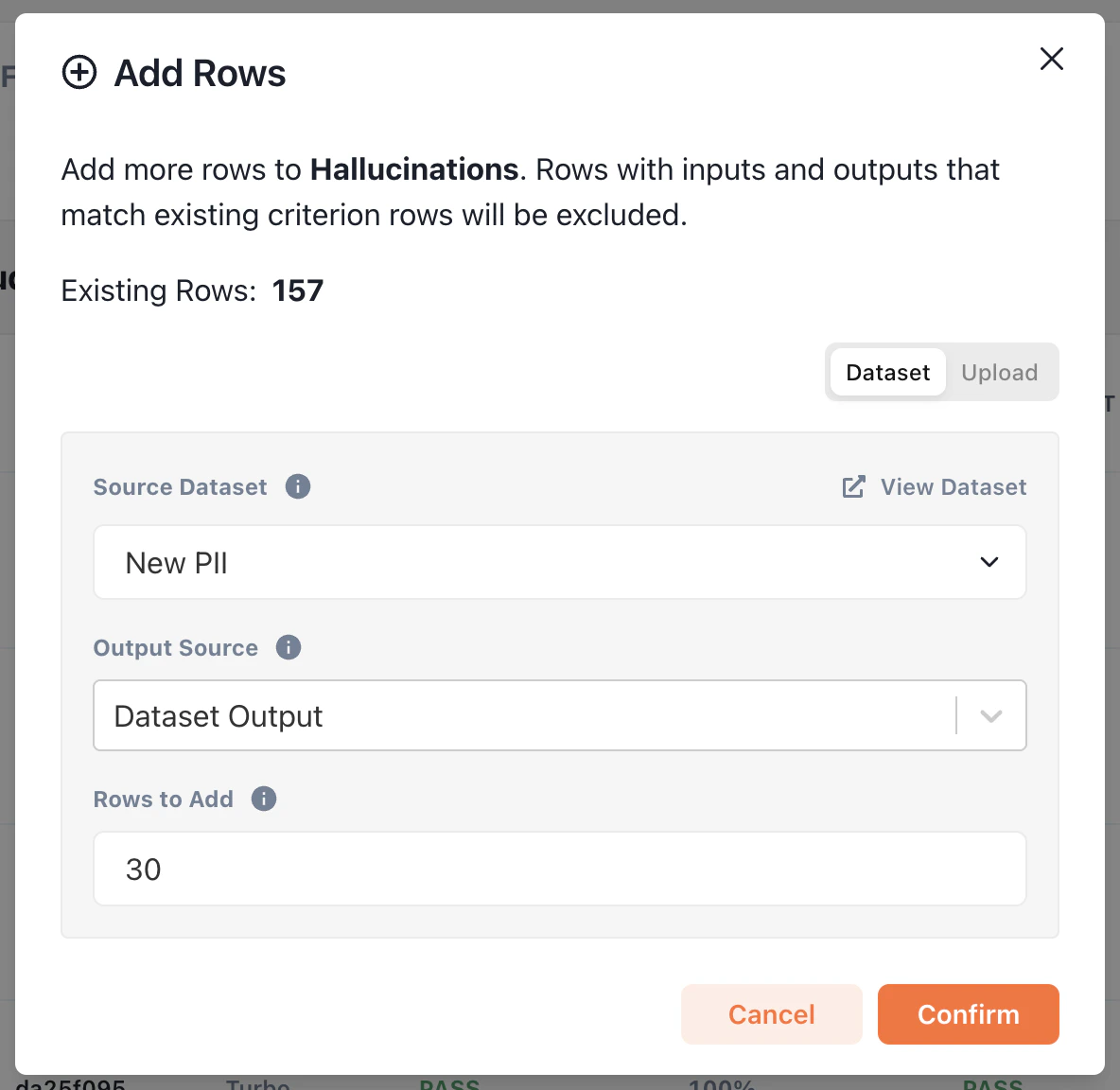
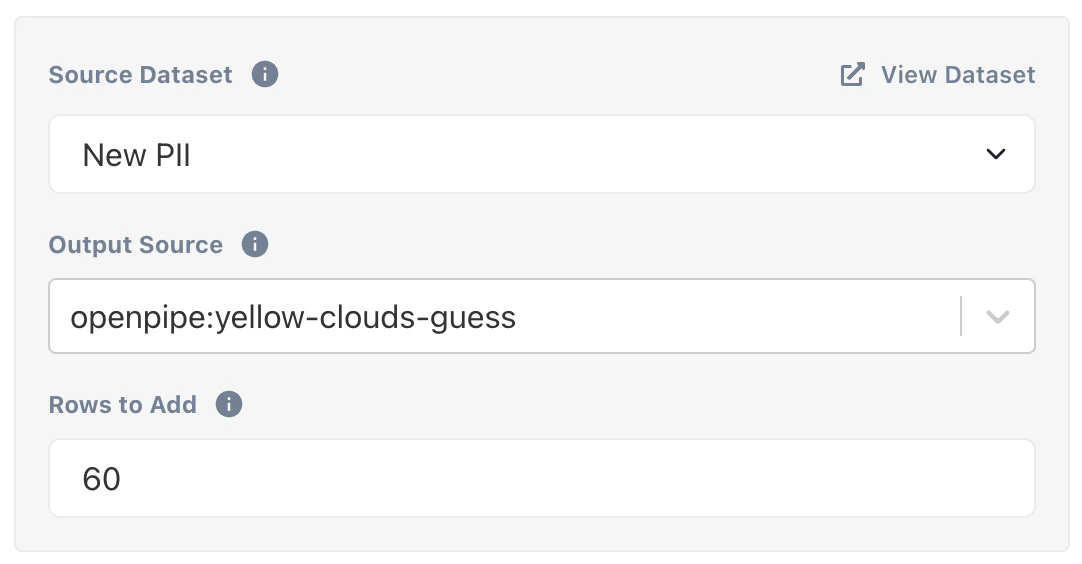
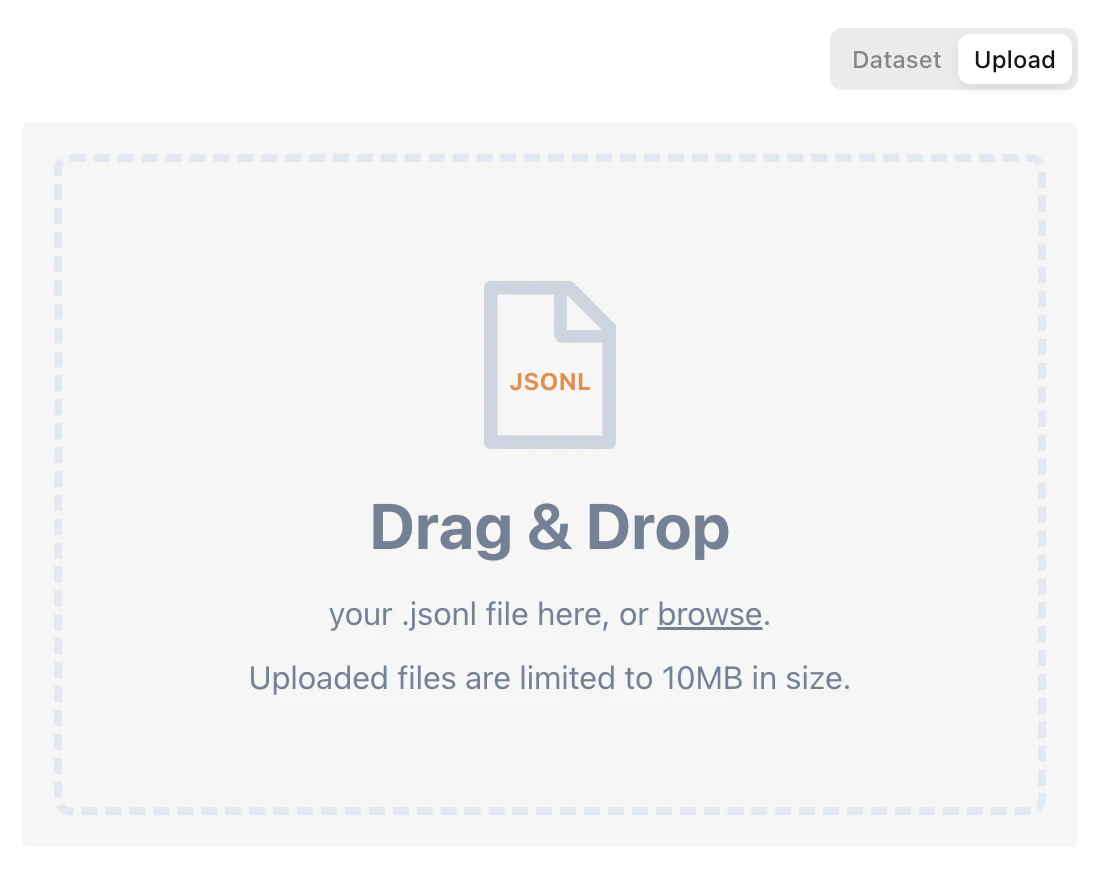
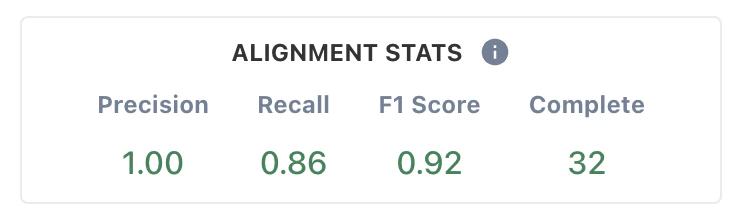
...
{"judgement": "PASS", "messages":[{"role":"system","content":"You are a helpful assistant"},{"role":"user","content":"What is the capital of Tasmania?"},{"role":"assistant","content":null,"tool_calls":[{"id":"","type":"function","function":{"name":"identify_capital","arguments":"{\"capital\":\"Hobart\"}"}}]}],"tools":[{"type":"function","function":{"name":"identify_capital","parameters":{"type":"object","properties":{"capital":{"type":"string"}}}}}]}
{"judgement": "FAIL", "messages":[{"role":"system","content":"You are a helpful assistant"},{"role":"user","content":"What is the capital of Sweden?"},{"role":"assistant","content":null,"tool_calls":[{"id":"","type":"function","function":{"name":"identify_capital","arguments":"{\"capital\":\"Beijing\"}"}}]}],"tools":[{"type":"function","function":{"name":"identify_capital","parameters":{"type":"object","properties":{"capital":{"type":"string"}}}}}]}
{"messages":[{"role":"system","content":"You are a helpful assistant"},{"role":"user","content":"What is the capital of Sweden?"},{"role":"assistant","content":null,"tool_calls":[{"id":"","type":"function","function":{"name":"identify_capital","arguments":"{\"capital\":\"Stockholm\"}"}}]}],"tools":[{"type":"function","function":{"name":"identify_capital","parameters":{"type":"object","properties":{"capital":{"type":"string"}}}}}]}
...