Code evaluations are not a good match for all tasks. They work well for deterministic tasks like
classification or information extraction, but not for tasks that produce freeform outputs like
chatbots or summarization. To evaluate tasks with freeform outputs, please consider criterion
evaluations.
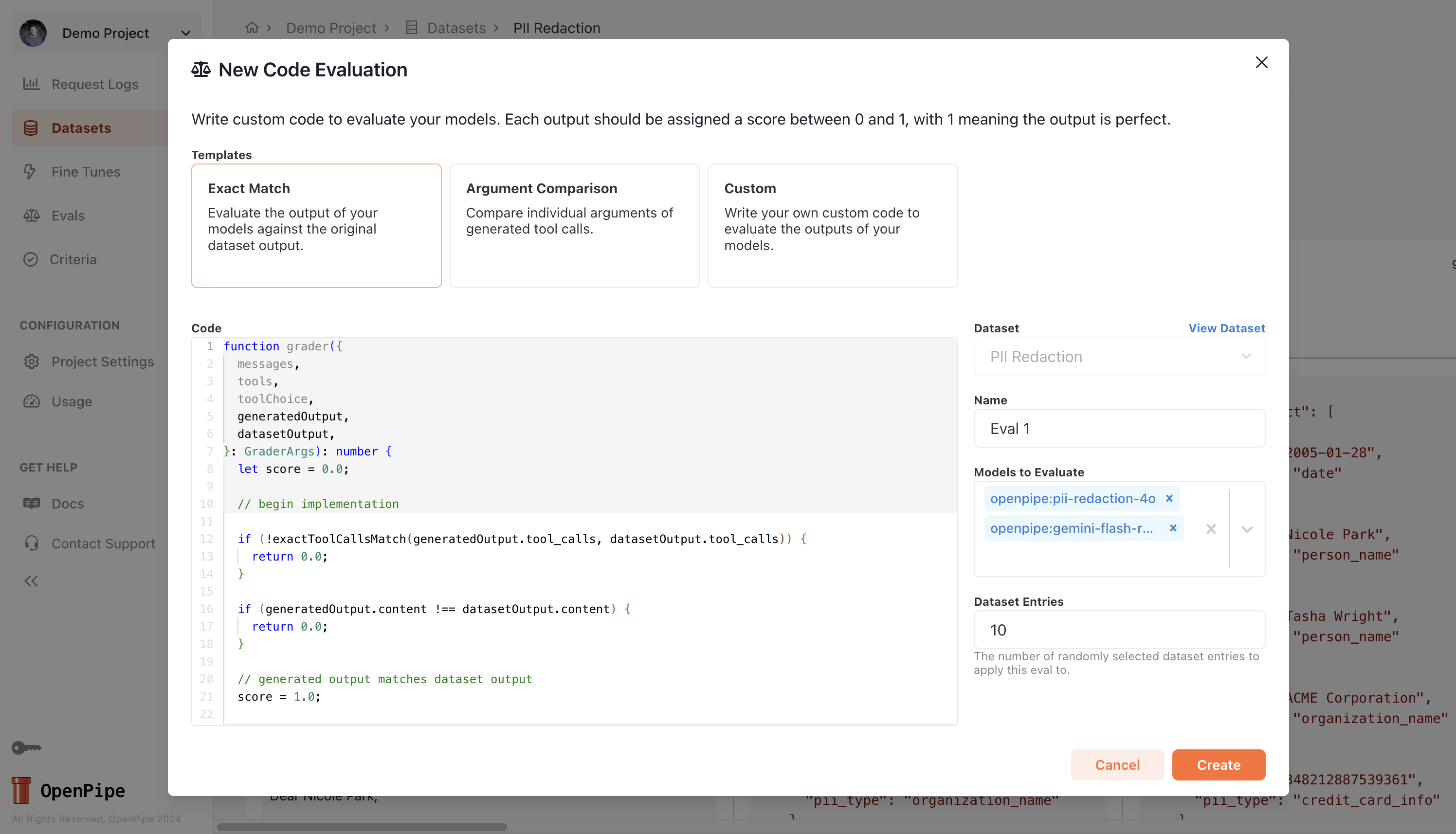
Each code eval consists of a templated
grader function that you can customize. Here’s the basic structure:
grader function takes in a number of arguments and returns a score between 0 and 1, where 1 means the generated output is perfect. The available arguments are:
messages: The messages sent to the LLM.tools: The tools available to the LLM.toolChoice: The tool choice specified for the LLM.generatedOutput: The output generated by the LLM which is being evaluated.datasetOutput: The original dataset output associated with the row being evaluated.
generatedOutput and datasetOutput to compare the output of the LLM to the dataset output.
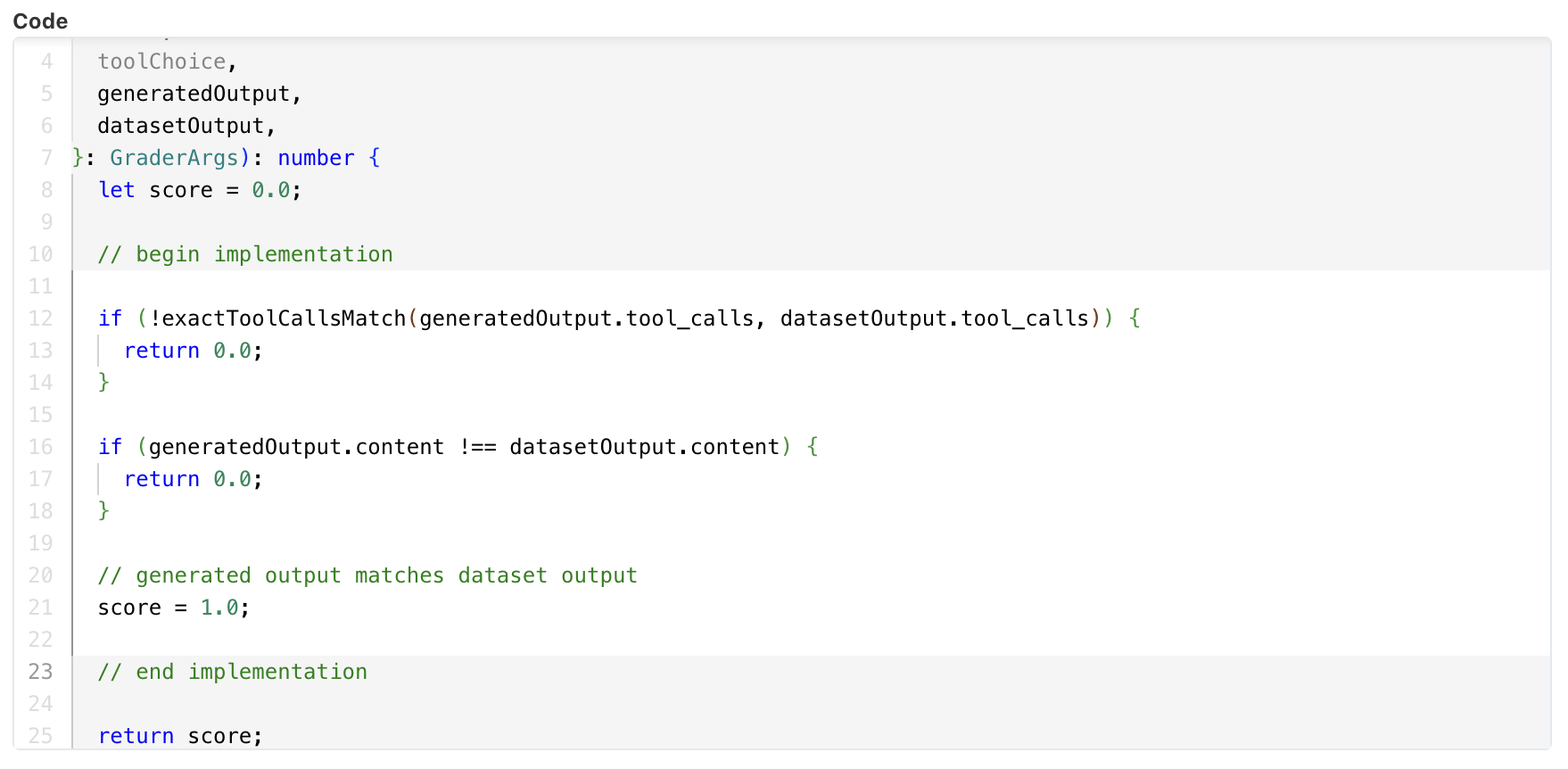
To get a better idea of what kinds of checks can be performed through a code evaluation, you can check out the Exact Match or Argument Comparison templates below.
Exact Match
Exact Match
The Exact Match template checks if the generated output matches the dataset output exactly, meaning that the content and tool calls must match exactly.
Argument Comparison
Argument Comparison
The Argument Comparison template provides an example of how you can check whether a specific argument in the tool call generated by the LLM matches the dataset output.
Currently, the code evaluation framework only supports TypeScript code executed in a sandbox
environment without access to the internet, external npm packages, or a file system. If you’re
interested in writing evals in other languages or need more advanced features, please let us know
at support@openpipe.ai.