- Serverless: shared endpoints with auto-scaling and per-token billing
- Hourly: shared endpoint for a less popular model that is billed by the compute unit
- Dedicated: single-tenant deployment that is billed through a monthly contract
Serverless
Our most popular base models are available through serverless deployments. Serverless deployments are shared across all users of a given base model, and are automatically scaled up and down in response to user demand. All usage is billed by the token. We recommend training models hosted on serverless endpoints when possible to take advantage of fast response times and flexible billing. Along with closed source models likegpt-4o and gemini-1.5-flash, the following open source base models can be fine-tuned and hosted on serverless endpoints:
meta-llama/Meta-Llama-3.1-8B-Instructmeta-llama/Meta-Llama-3.1-70B-Instruct
Hourly
As with serverless deployments, base models hosted on hourly deployments are also shared across users. They are billed by the compute unit, which corresponds to the amount of time that a model ran on a GPU while processing a request. While many models are available through hourly deployments, they are prone to cold start times, which can be a problem for latency-sensitive tasks. If no request has been made to a given base model (e.g. Qwen 2.5 7B Instruct) for over 5 minutes, the next request to any model trained on that base will have to wait for the entire model to be downloaded to a GPU. If you need to run a model that is not available through a serverless deployment for a latency-sensitive task, we recommend using a dedicated deployment.Dedicated
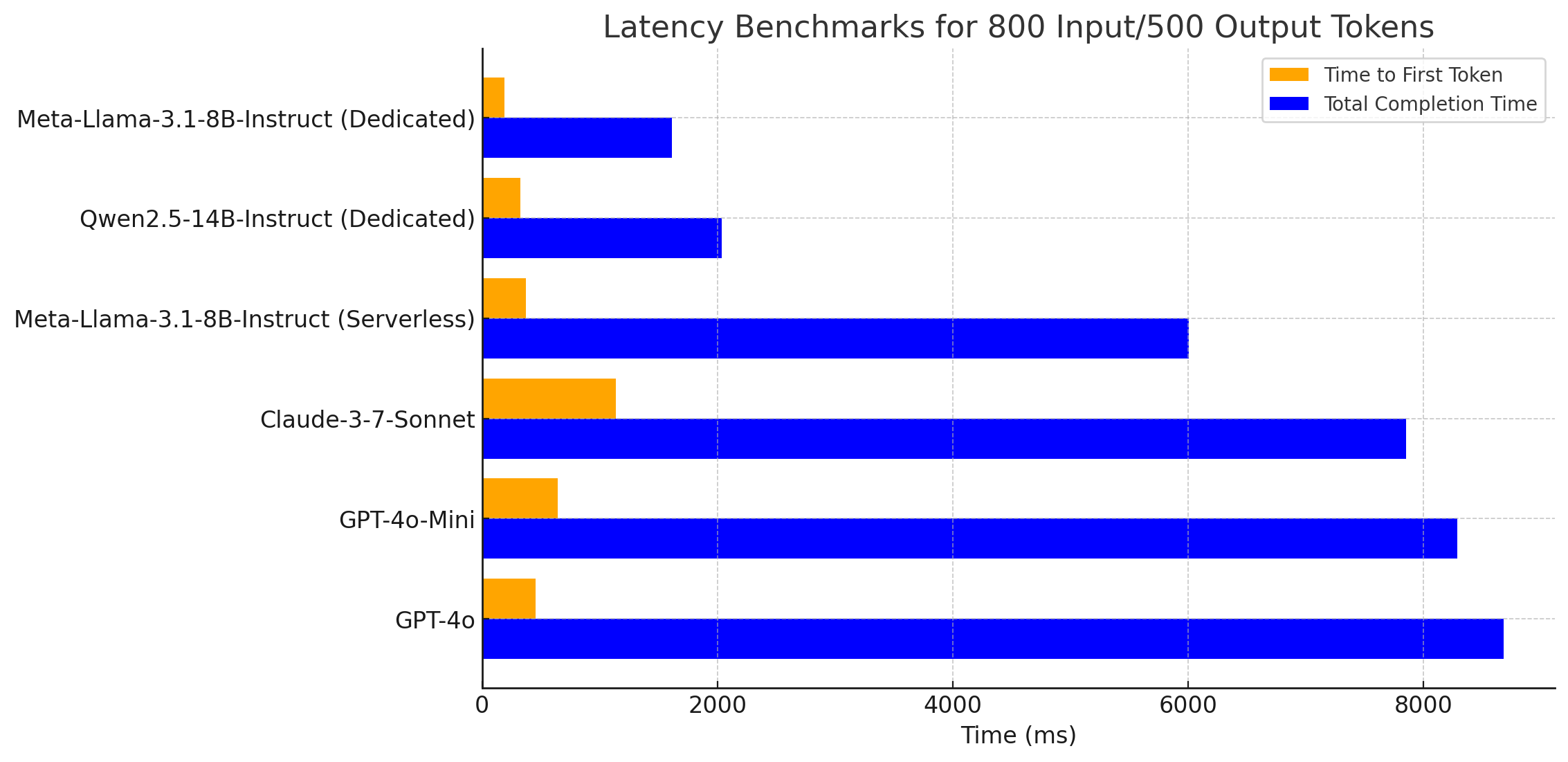
Dedicated deployments are single-tenant and are billed based on a monthly contract. Unlike serverless and hourly deployments, they can be served as merged models. Through speculative decoding, prefix caching, and other techniques, dedicated deployments can provide much faster response times for latency-sensitive tasks. Any fine-tuned model can be deployed on a dedicated endpoint. The cost of the deployment is determined by the size of the model and the number of concurrent requests it needs to support.Latency Benchmarks
While every task is different, we’ve found that models hosted on dedicated deployments generally provide much faster response times than those hosted on serverless and hourly endpoints. Both time to first token and total completion time are often reduced by 50% or more. The following chart shows the average time to first token and total completion time for three models hosted on OpenPipe, and three popular closed source models. The dedicated deployments are equipped with n-gram speculative decoding, allowing the model to “guess” several tokens at a time, then validate the guess with the fully trained model. In practice this reduces latency by avoiding bottlenecks in the GPU without any degradation in accuracy.