Before you begin: Before writing your first eval, make sure you’ve created a
dataset with one or more test entries. Also, make sure to add
your OpenAI or Anthropic API key in your project settings page to allow the judge LLM to run.
Writing an Evaluation
1
Choose a dataset to evaluate models on
To create an eval, navigate to the dataset with the test entries you’d like to evaluate your models based on.
Find the Evaluate tab and click the + button to the right of the Evals dropdown list.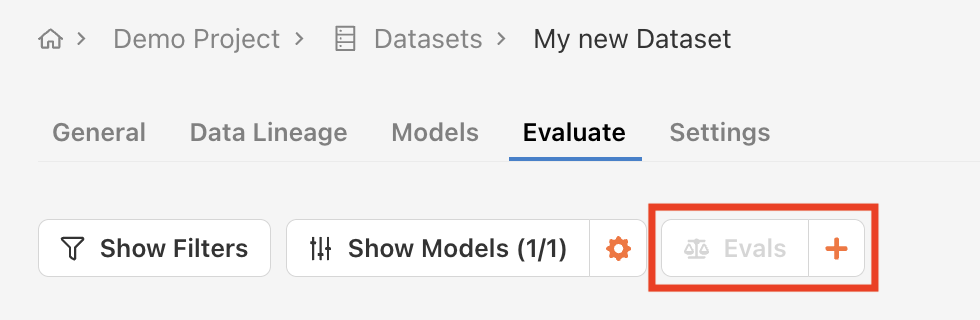
2
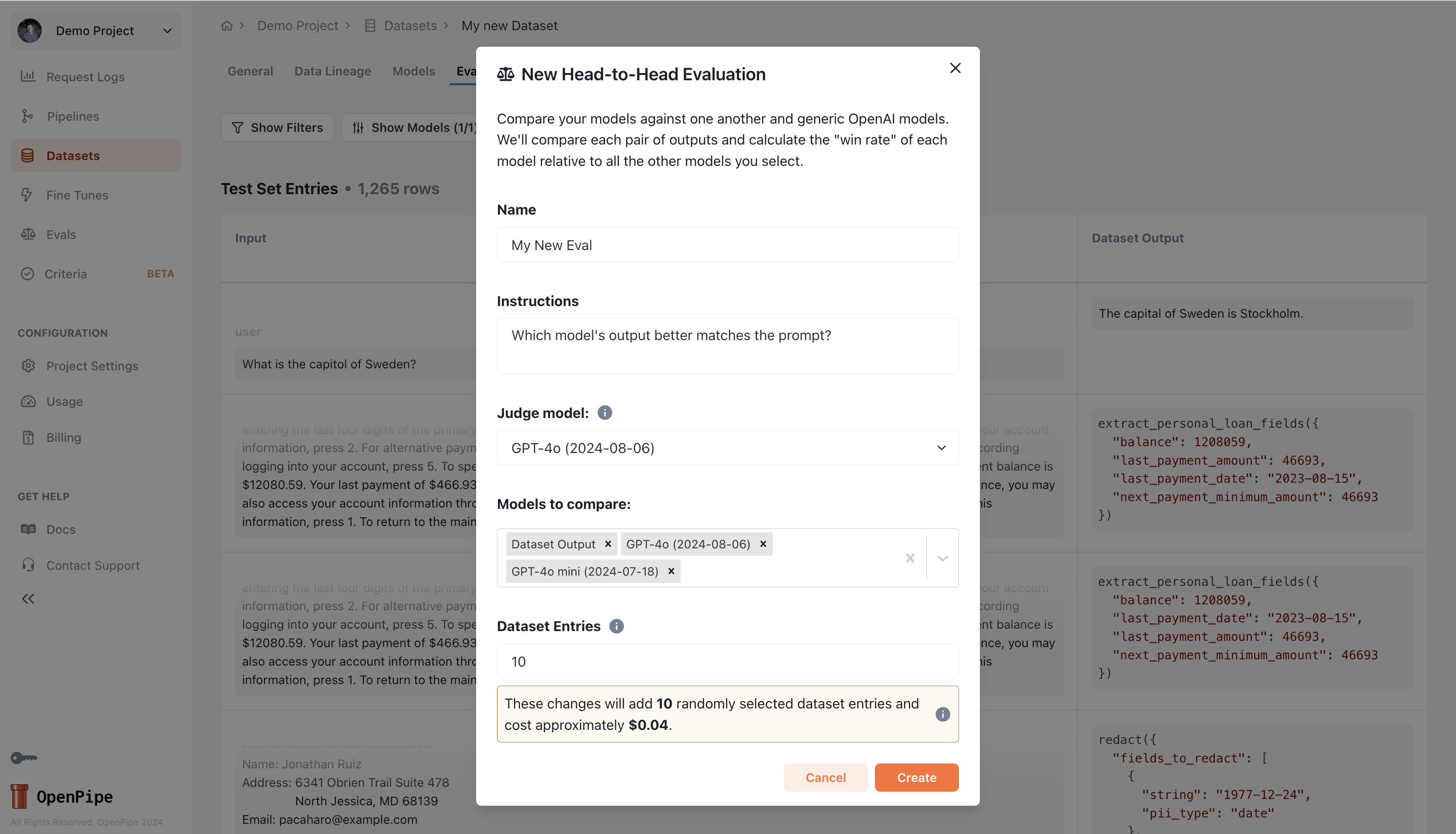
Edit judge model instructions
Customize the judge LLM instructions. The outputs of each model will be compared against one another
pairwise and a score of WIN, LOSS, or TIE will be assigned to each model’s based on the judge’s instructions.
3
Select judge model
Choose a judge model from the dropdown list. If you’d like to use a judge model that isn’t supported by default,
add it as an external model in your project settings page.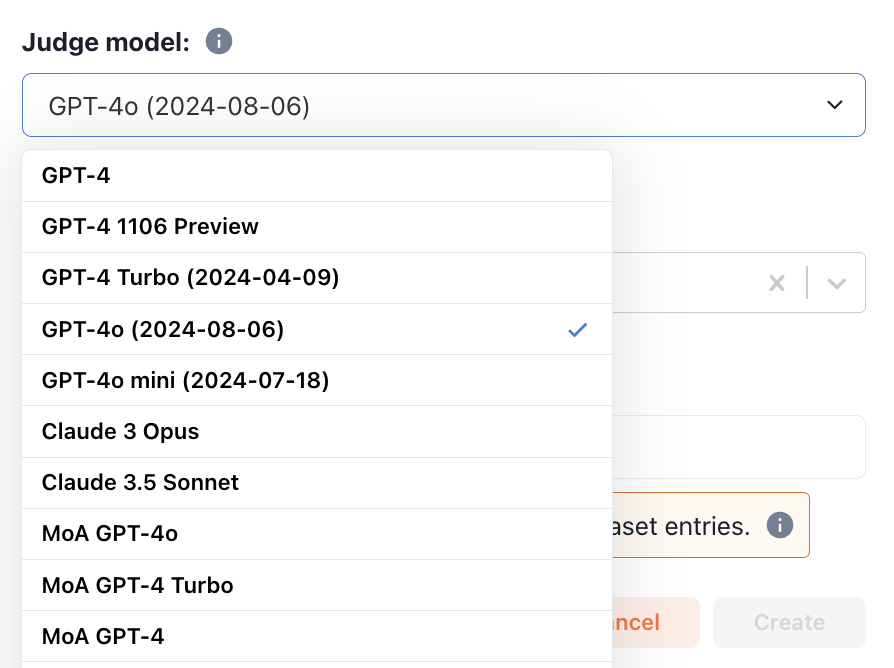
4
Choose models to evaluate
Choose the models you’d like to evaluate against one another.
5
Run the evaluation
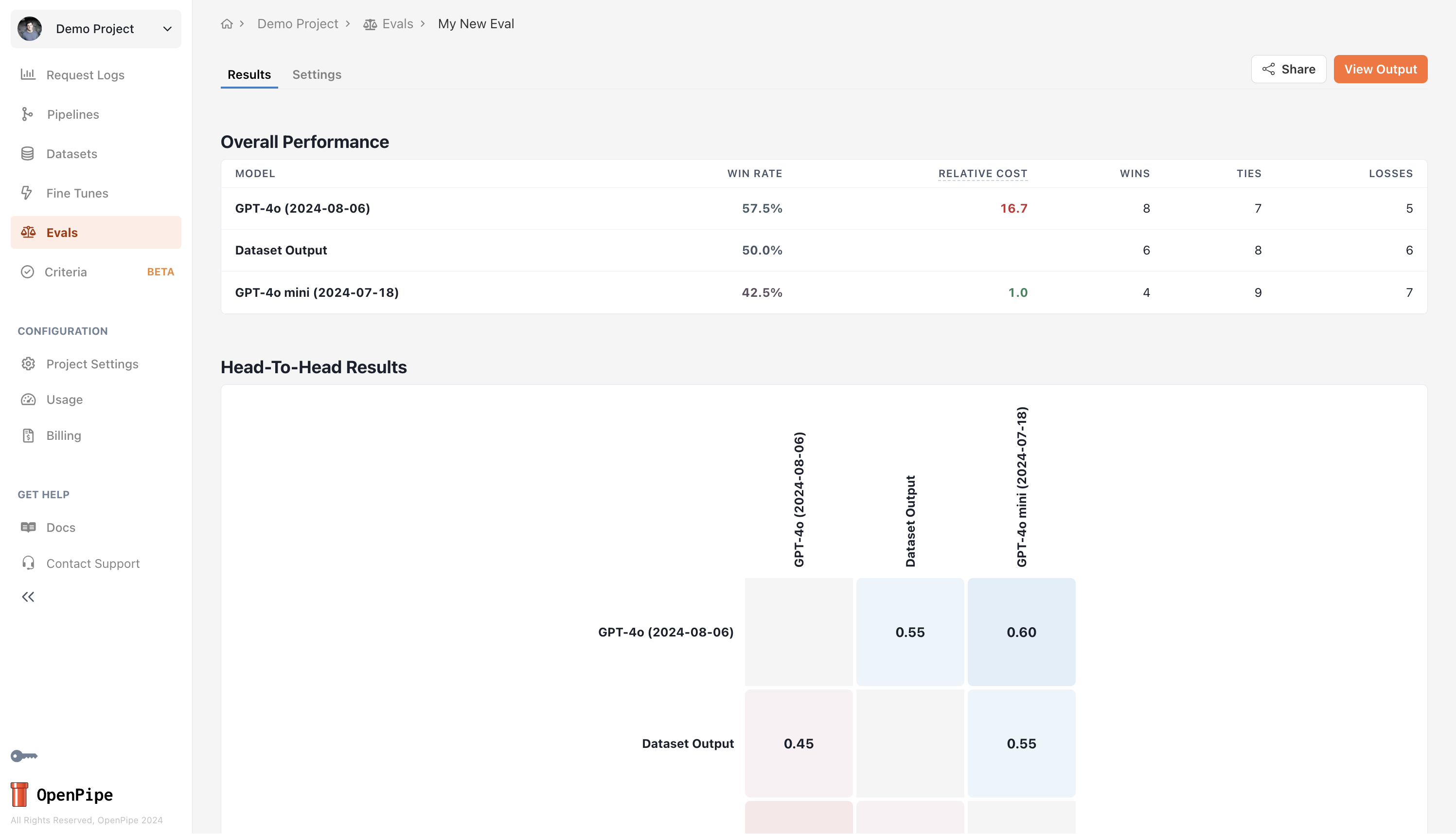
Click Create to start running the eval.Once the eval is complete, you can see model performance in the evaluation’s Results tab.