Preparing preference data
Currently, OpenPipe supports training reward models from preference data (training reward models based on rewards directly is in the works). Preference data is a dataset of pairs of responses in which one response is better than another. One way to gather such a dataset is to present users with two LLM completions and ask them to select the better one. Another way is to allow users to regenerate a response until they are satisfied with the output, then associate the original and final generated responses as a pair, with the final response being the preferred one. Whether you gather your preference data from your users or through a different process, it needs to match the JSONL preference data format shown below:rejected_message field should contain the rejected response, and the final assistant message should be the preferred response. Conveniently, this is the same data format used for DPO, which allows you to train both reward and completion models from the same dataset.
Training a reward model
Once you’ve added your preference data to a dataset, you can train a reward model by opening the “Reward Model” modal on the dataset page.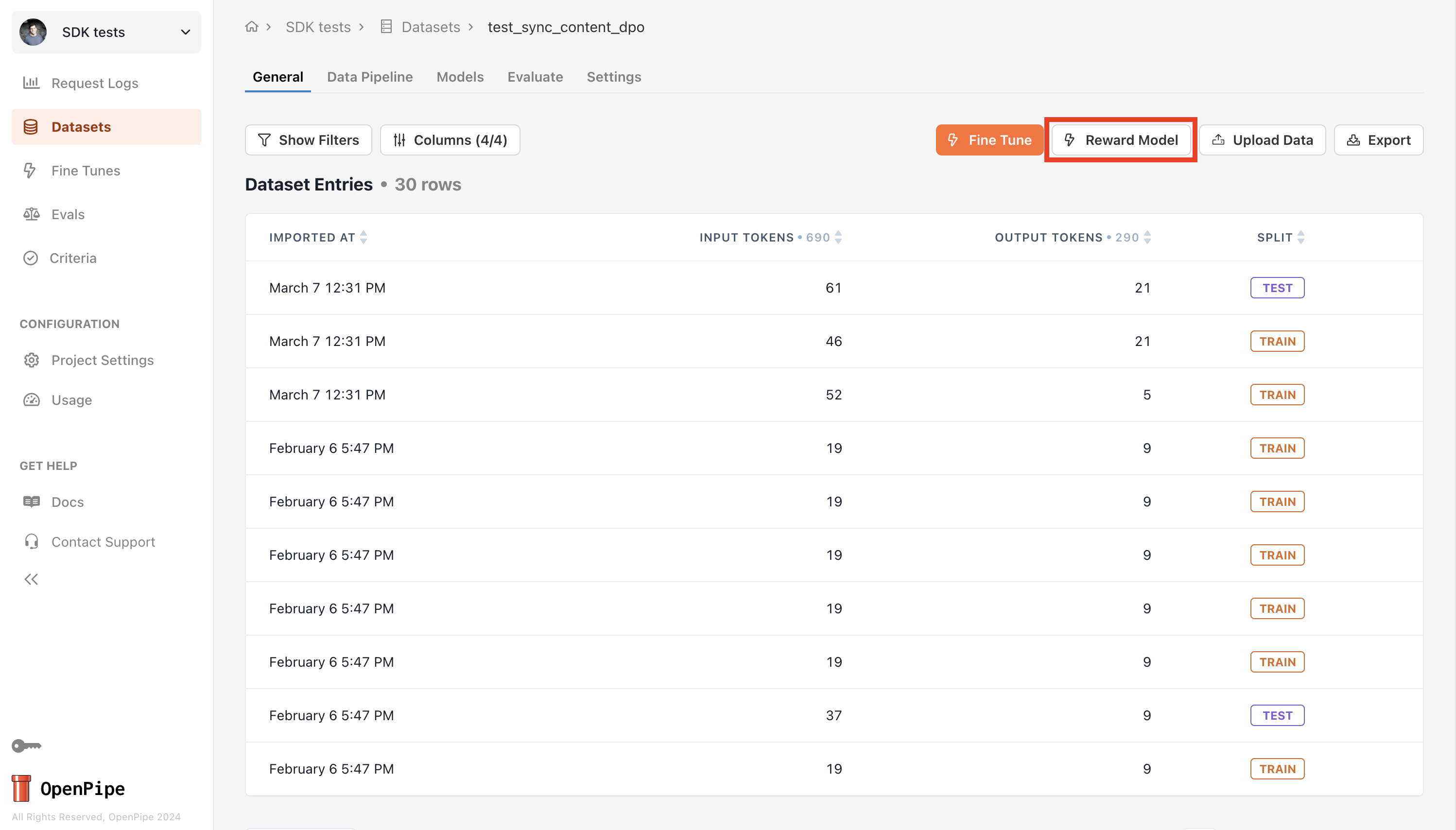
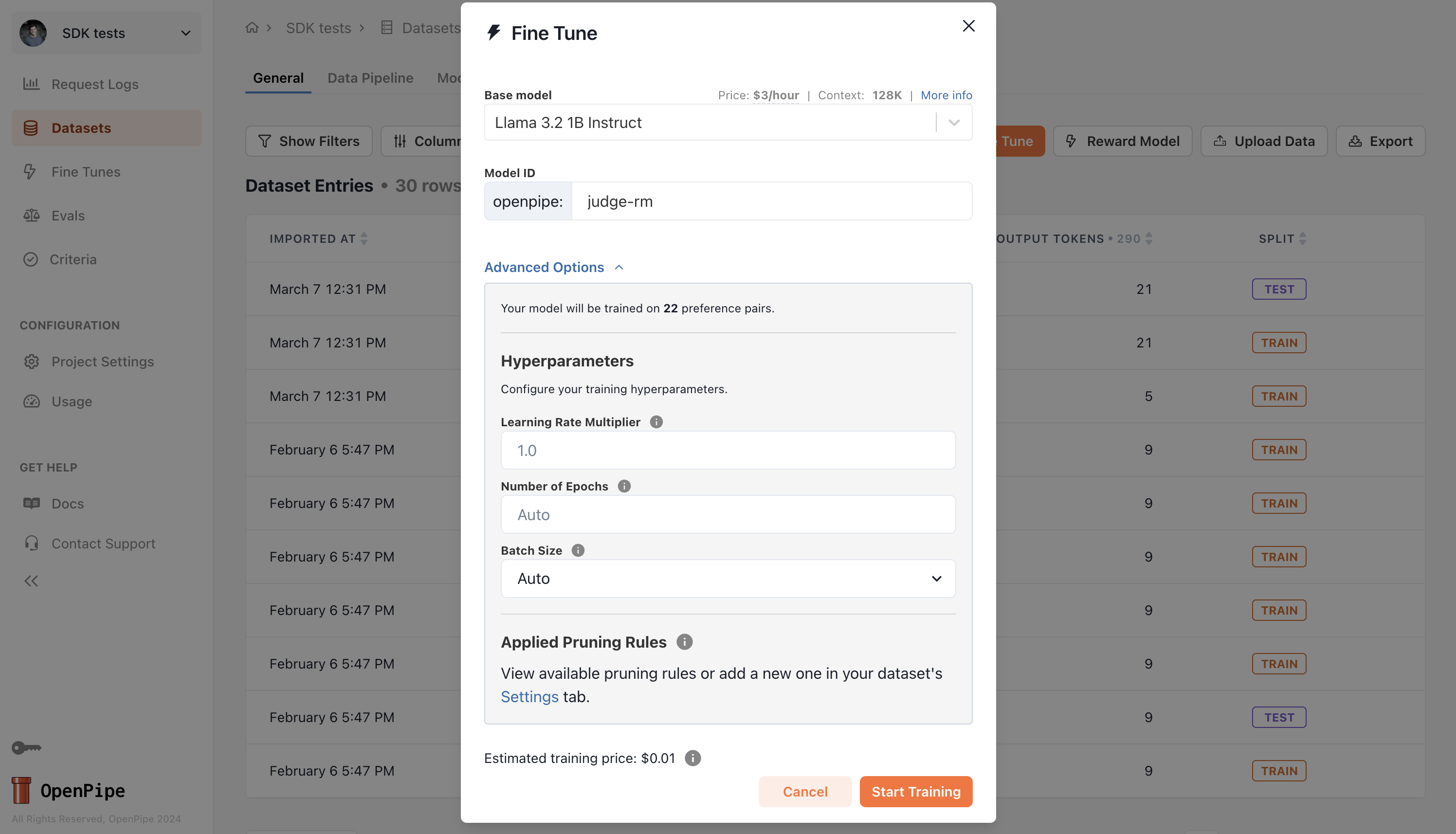
Using a reward model
Like criteria, reward models can be used for best of N sampling and offline evaluation. Reward model slugs can be specified independently or in conjunction with criteria, as shown below:Want to learn more about reward models? Send questions to support@openpipe.ai.