DPO is much harder to get right than supervised fine-tuning, and the results may not always be
better. To get the most out of DPO, we recommend familiarizing yourself with your specific use
case, your dataset, and the technique itself.
Gathering Preference Data
DPO is useful when you have a source of preference data that you can exploit. There are many possible sources of preference data, depending on your use case:- Expert Feedback: you may have a team of experts who can evaluate your model’s outputs and edit them to make them better. You can use the original and edited outputs as rejected and preferred outputs respectively. DPO can be effective with just a few preference pairs.
- Criteria Feedback: if you use OpenPipe criteria or another evaluation framework that assigns a score or pass/fail to an output based on how well it meets certain criteria, you can run several generations and use the highest and lowest scoring outputs as preferred and non-preferred outputs respectively.
- User Choice: if you have a chatbot-style interface where users can select their preferred response from a list of generated outputs, you can use the selected and rejected outputs as preference data.
- User Regenerations: if a user is able to regenerate an action multiple times and then eventually accepts one of the outputs, you can use the first output they rejected as a non-preferred output and the accepted output as a preferred output.
- User Edits: if your model creates a draft output and the user is able to edit it and then save, you can use the original draft as a non-preferred output and the edited draft as a preferred output.
Dataset Format
If uploading a dataset for DPO, ensure you include arejected_message field for each entry. This field should contain an output that model should avoid generating.
Example Use Cases
Initial tests with DPO on OpenPipe have shown promising results. DPO, when used with user-defined criteria, allows you to fine-tune models that more consistently respect even very nuanced preferences.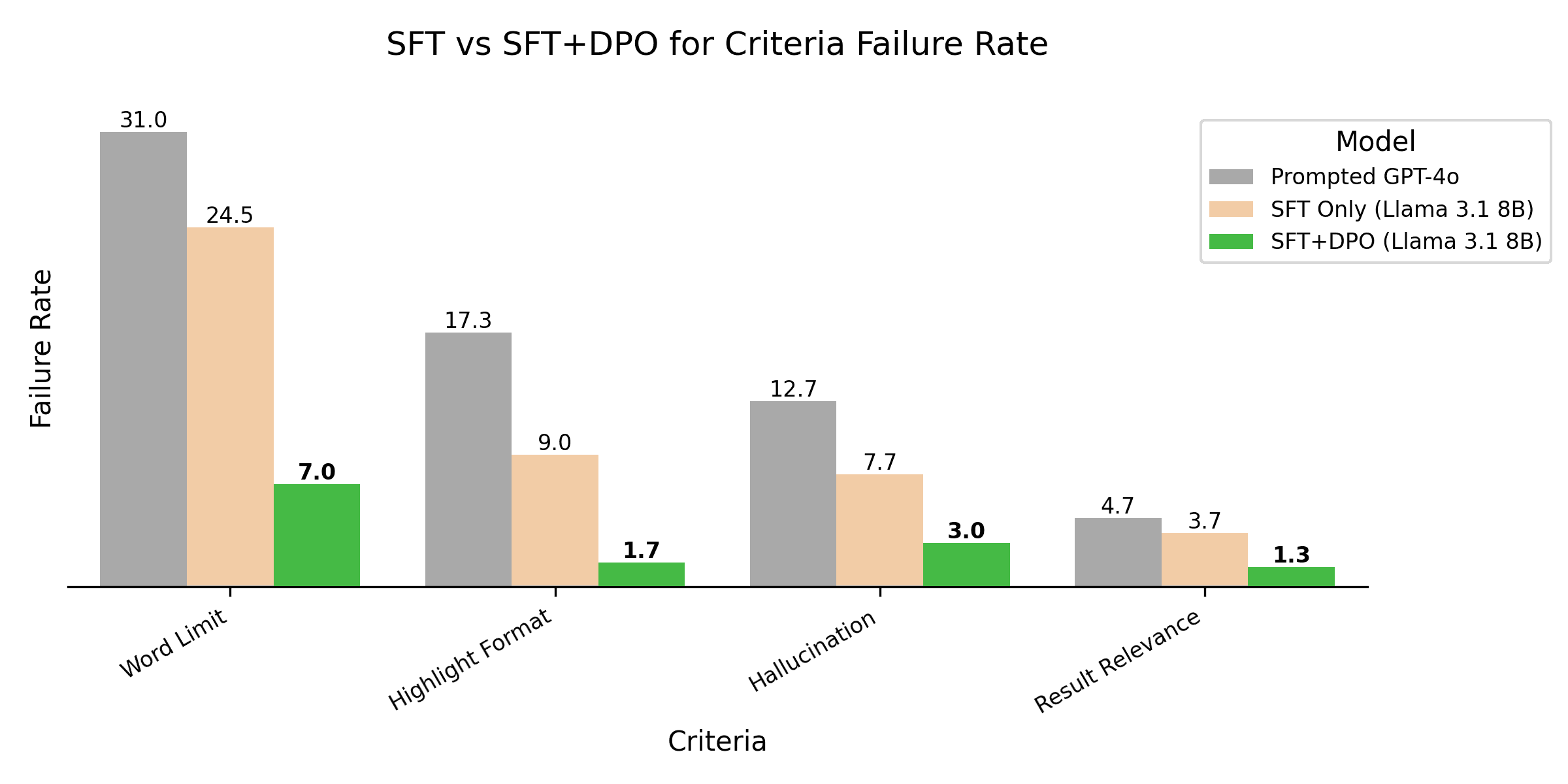
- Word Limit: for a summarization task with an explicit word limit given in the prompt, DPO was able to cut the number of responses exceeding the limit from 31% to 7%, a 77% decrease.
- Highlight Format: for a content formatting task, DPO was able to drop the percentage of times the wrong word or phrase was highlighted from 17.3% to 1.7%, a 90% decrease.
- Hallucination: for an information extraction task, DPO was able to drop the fraction of outputs with hallucinated information from 12.7% to 3.0%, a 76% decrease.
- Result Relevance: for a classification task determining whether a result was relevant to a query, DPO was able to drop the mis-classification rate from 4.7% to 1.3%, a 72% decrease.