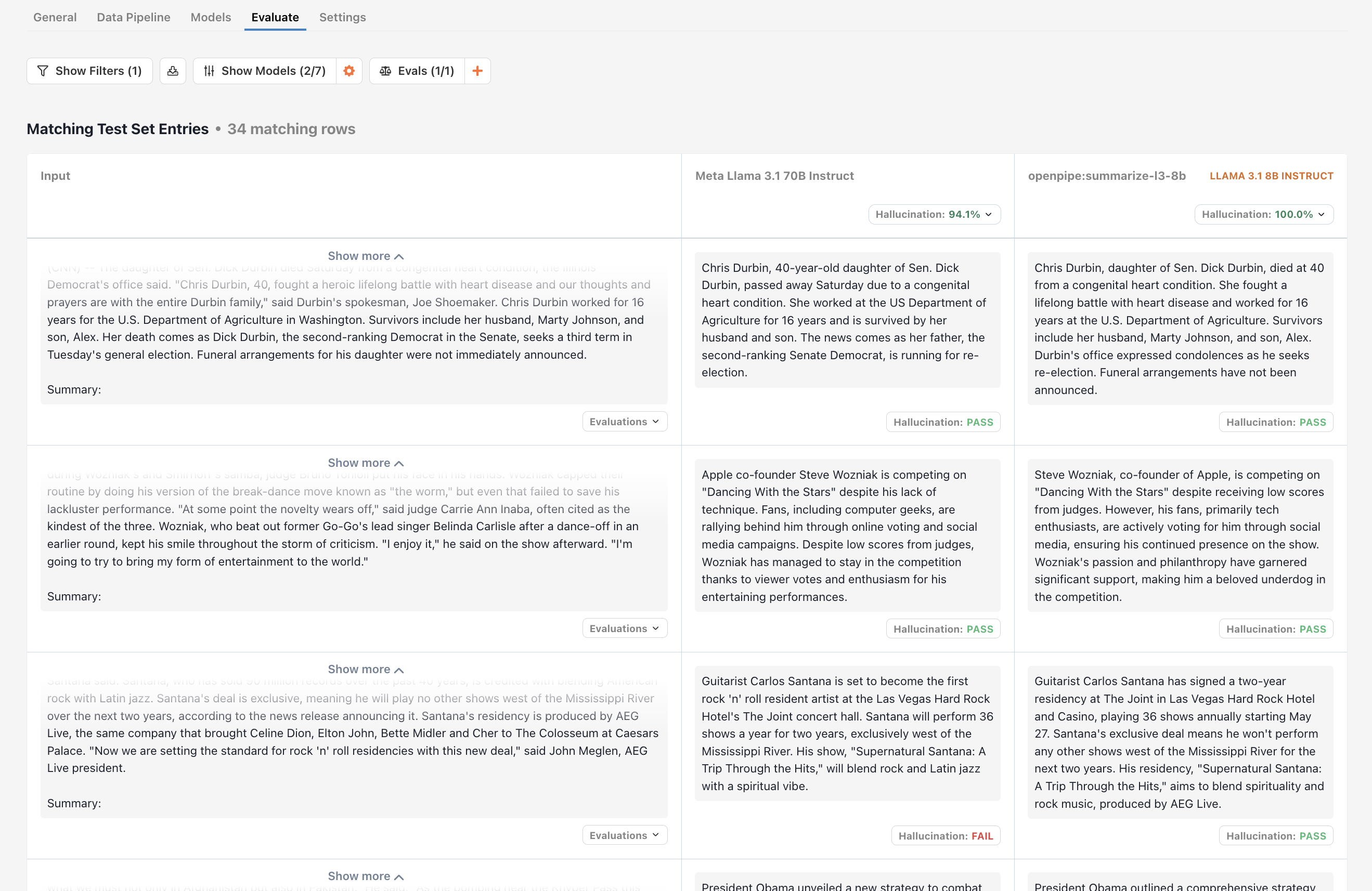
Viewing outputs side by side is useful, but it doesn’t tell you which model is doing better in general. For that, we need to define evaluations. Evaluations allow you to compare model outputs across a variety of inputs to determine which model is doing a better job. While each type of evaluation has its own unique UI, they all show final results in a sorted table.
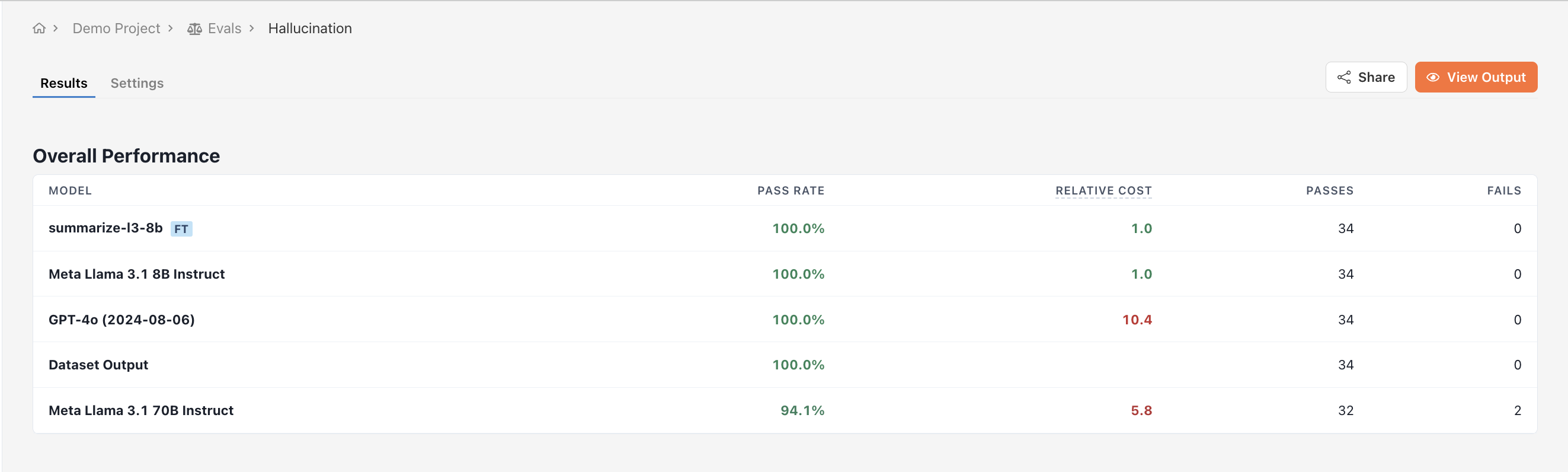
Datasets support three types of evaluations: As a rough guide, use code evaluations for deterministic tasks like classification or information extraction. Use criterion evaluations for tasks with freeform outputs like chatbots or summarization. Use head-to-head evaluations for comparing two or more models against each other if you’re looking for a quick and dirty way to compare model outputs.