> ## Documentation Index
> Fetch the complete documentation index at: https://docs.openpipe.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Chat Completions
Once your fine-tuned model is deployed, you're ready to start generating chat completions.
First, make sure you've set up the SDK properly. See the [OpenPipe SDK](/getting-started/openpipe-sdk) section for more details. Once the SDK is installed and you've added the right
`OPENPIPE_API_KEY` to your environment variables, you're almost done.
The last step is to update the model that you're querying to match the ID of your new fine-tuned model.
```python theme={null}
from openpipe import OpenAI
# Find the config values in "Installing the SDK"
client = OpenAI()
completion = client.chat.completions.create(
# model="gpt-4o", - original model
model="openpipe:your-fine-tuned-model-id",
messages=[{"role": "system", "content": "count to 10"}],
metadata={"prompt_id": "counting", "any_key": "any_value"},
)
```
```typescript theme={null}
import OpenAI from "openpipe/openai";
// Find the config values in "Installing the SDK"
const client = OpenAI();
const completion = await client.chat.completions.create({
// model: "gpt-4o", - original model
model: "openpipe:your-fine-tuned-model-id",
messages: [{ role: "user", content: "Count to 10" }],
metadata: {
prompt_id: "counting",
any_key: "any_value",
},
});
```
Queries to your fine-tuned models will now be shown in the [Request Logs](/features/request-logs) panel.
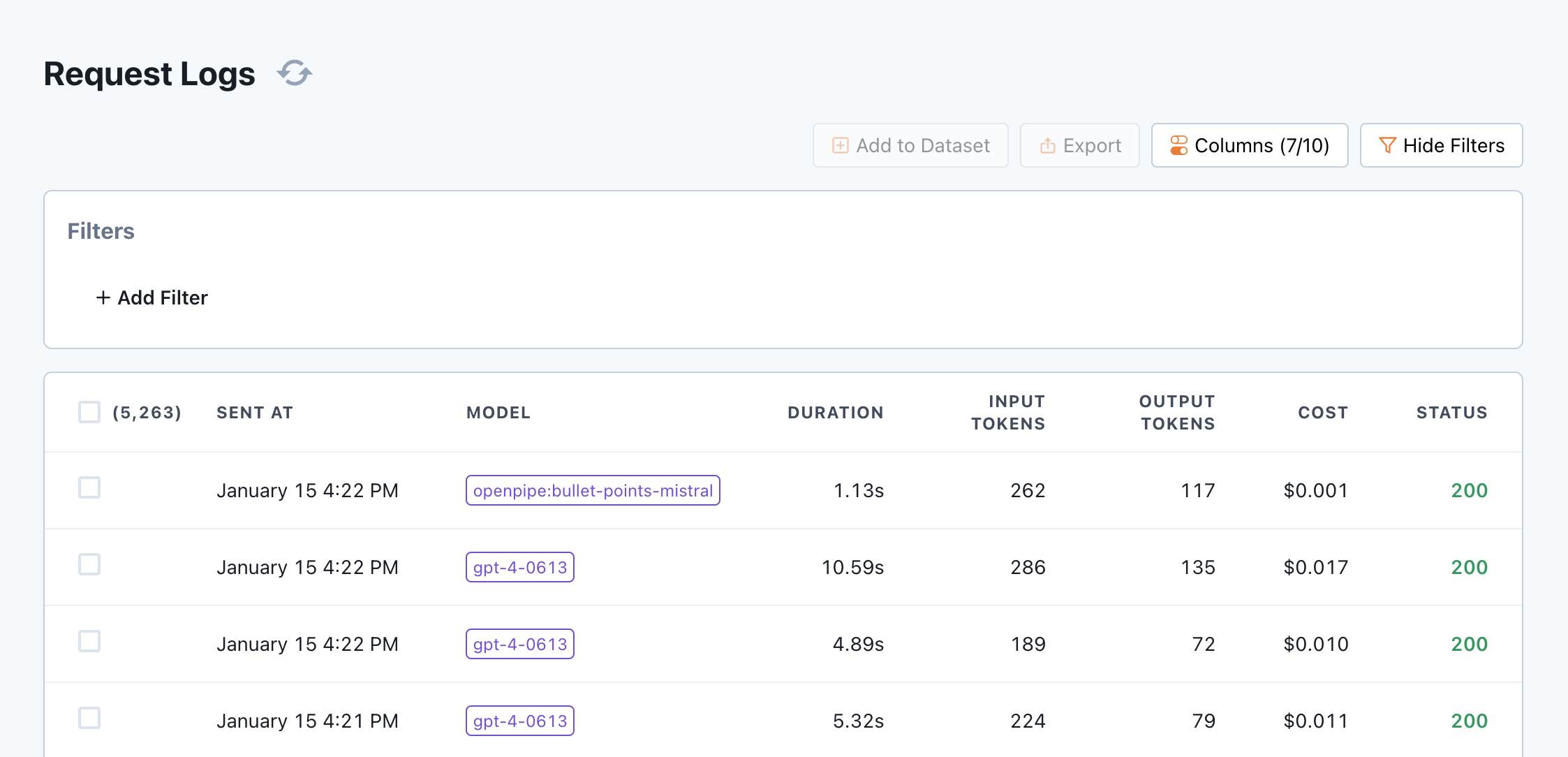 Feel free to run some sample inference on the [PII Redaction model](https://app.openpipe.ai/p/BRZFEx50Pf/fine-tunes/efb0d474-97b6-4735-a0af-55643b50600a/general) in our public project.
Feel free to run some sample inference on the [PII Redaction model](https://app.openpipe.ai/p/BRZFEx50Pf/fine-tunes/efb0d474-97b6-4735-a0af-55643b50600a/general) in our public project.